Crawling¶
Content Chimera can import assets in two ways: crawling and importing (see Data Sources). Whereas most crawlers are optimized for either one or both of: a) SEO or b) generating lists of URLs, Content Chimera’s crawler is optimized for gathering content useful for content decisions. Furthermore, it is built for large crawls and to give visibility into the crawl status.
Starting a crawl¶
To start a crawl, go to the Assets & Metadata page and click on the Start Crawling button.
In the majority of cases the defaults are sufficient (see Crawl Options).
Note
You don’t necessarily have to know more about crawling than how to click on Start Crawling. The information below is especially useful for larger crawls or if you run into any issues.
The steps of crawling¶
If the crawl is running successfully, you will see three progress circles (with some activity in at least the first circle), “Status: Running”, and the circle next to the Cancel button will be changing:
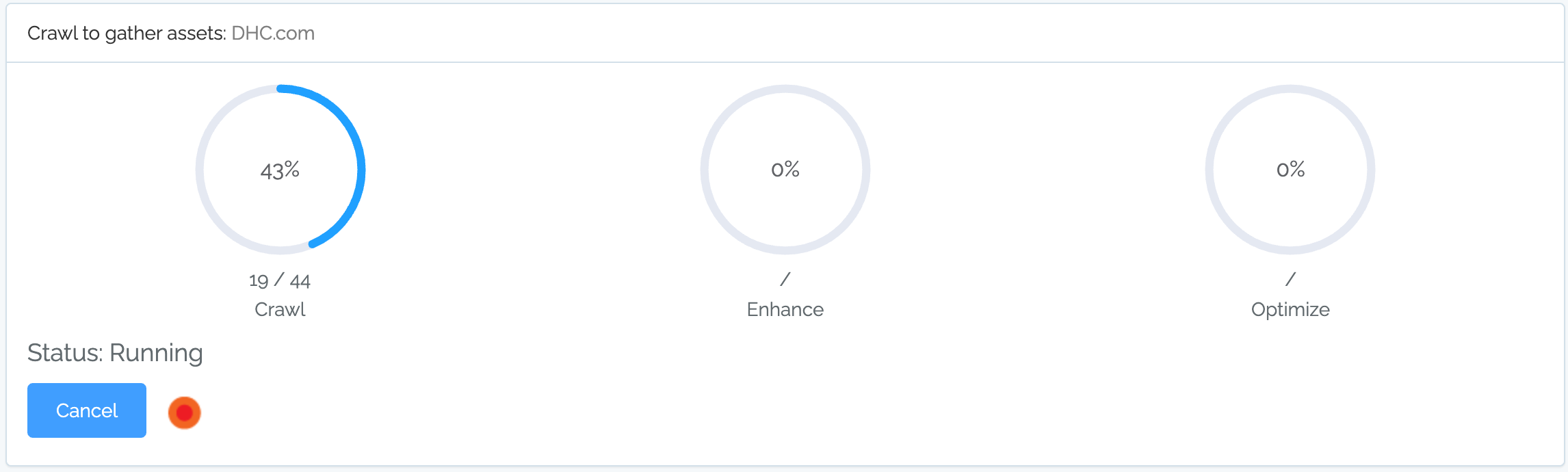
When you first start the crawl, it will go through the following statuses (it may happen so fast that you do not see all the steps before Running):
Unknown
Queued
Running
There are a couple other normal statuses (these statuses happen after clicking Cancel):
Requested Termination
Successfully Terminated.
Watching crawls¶
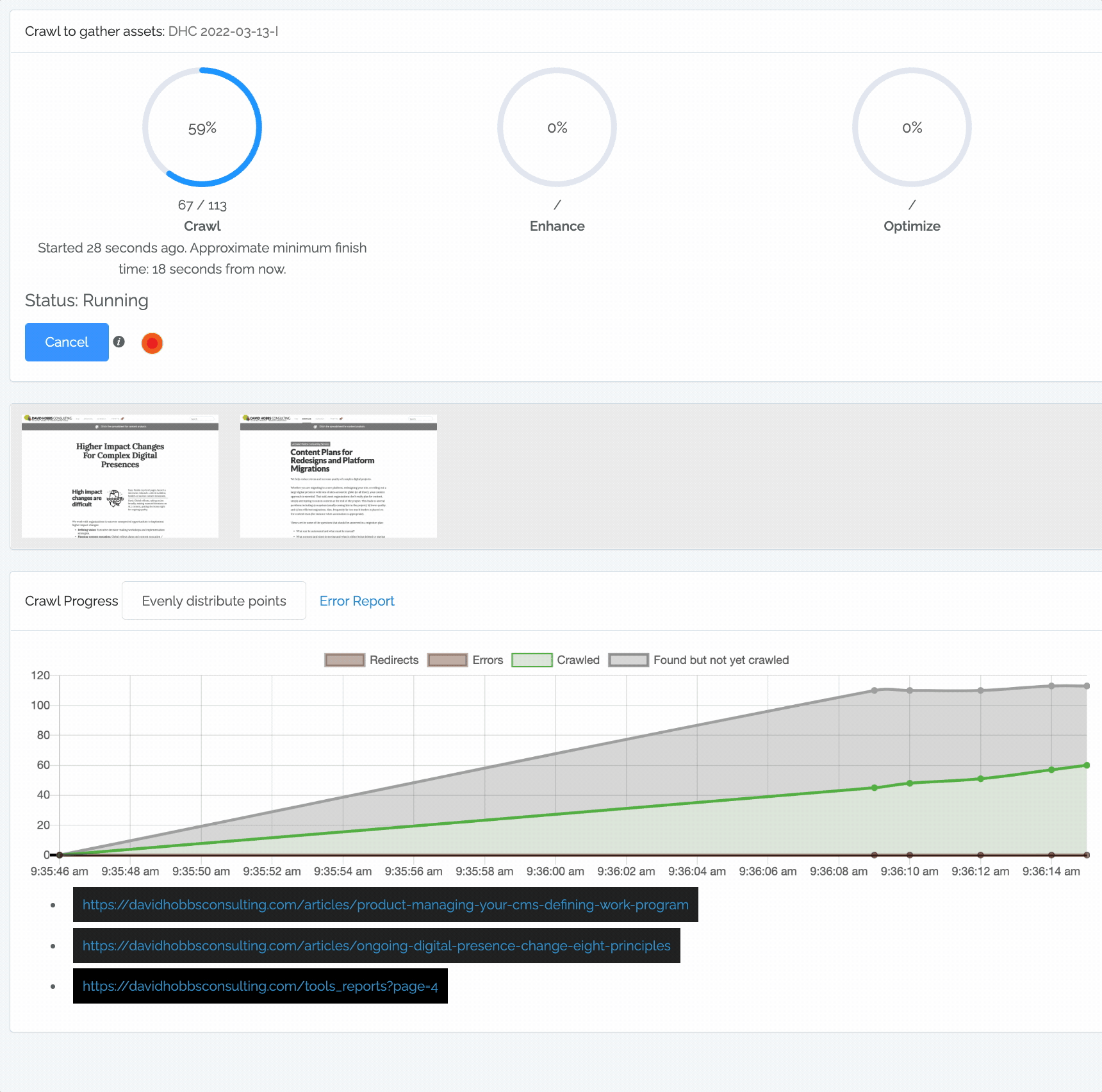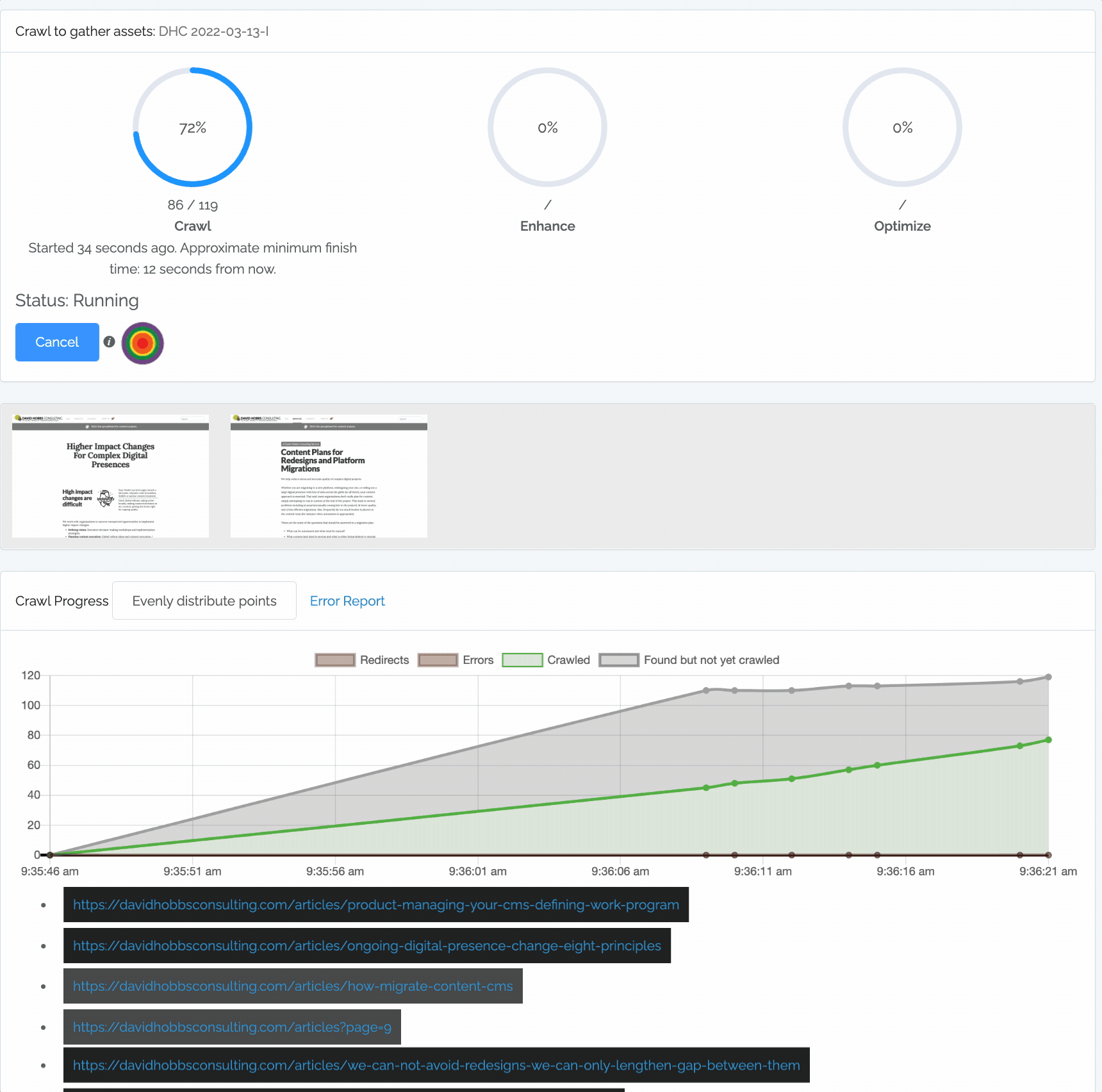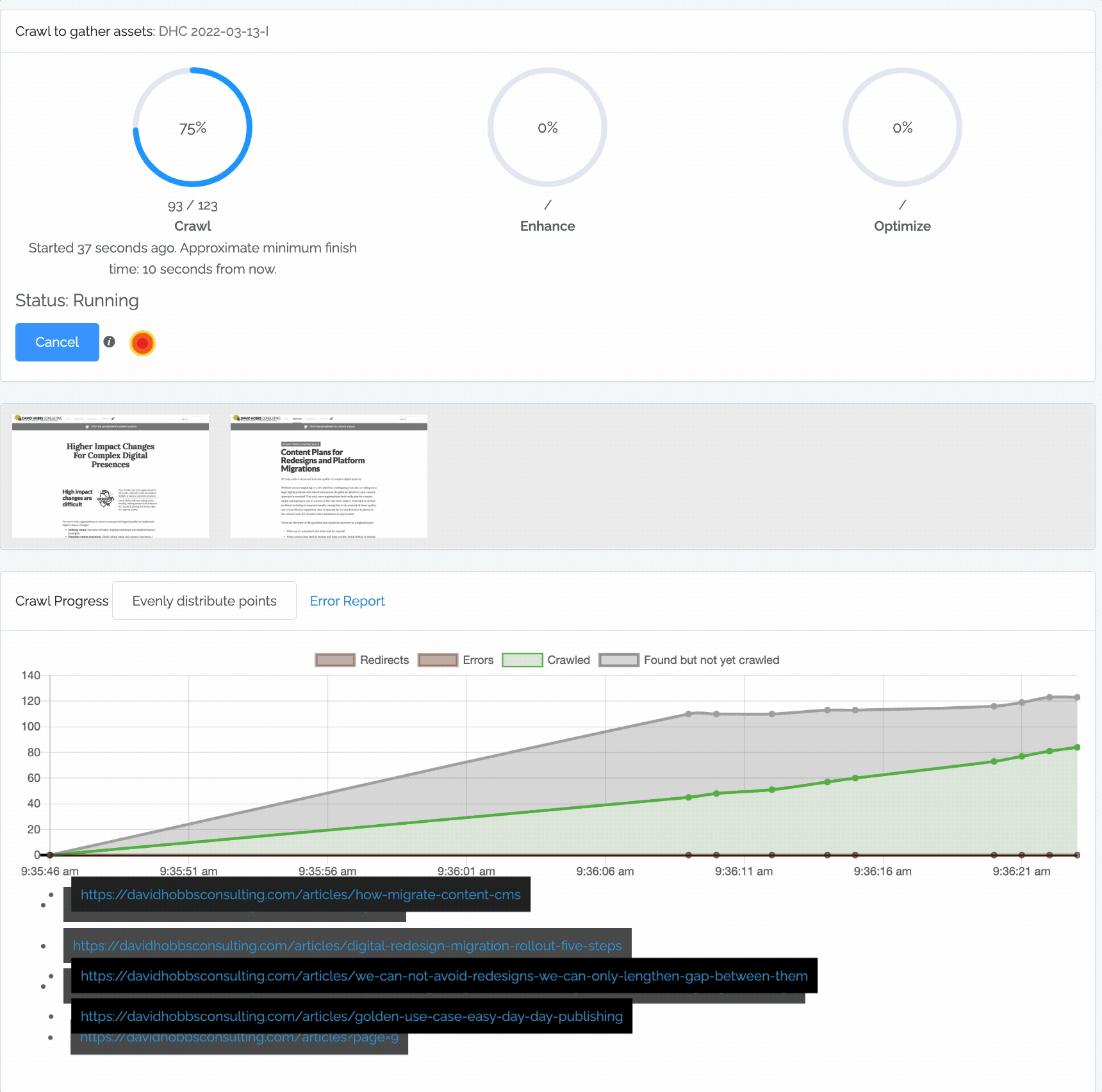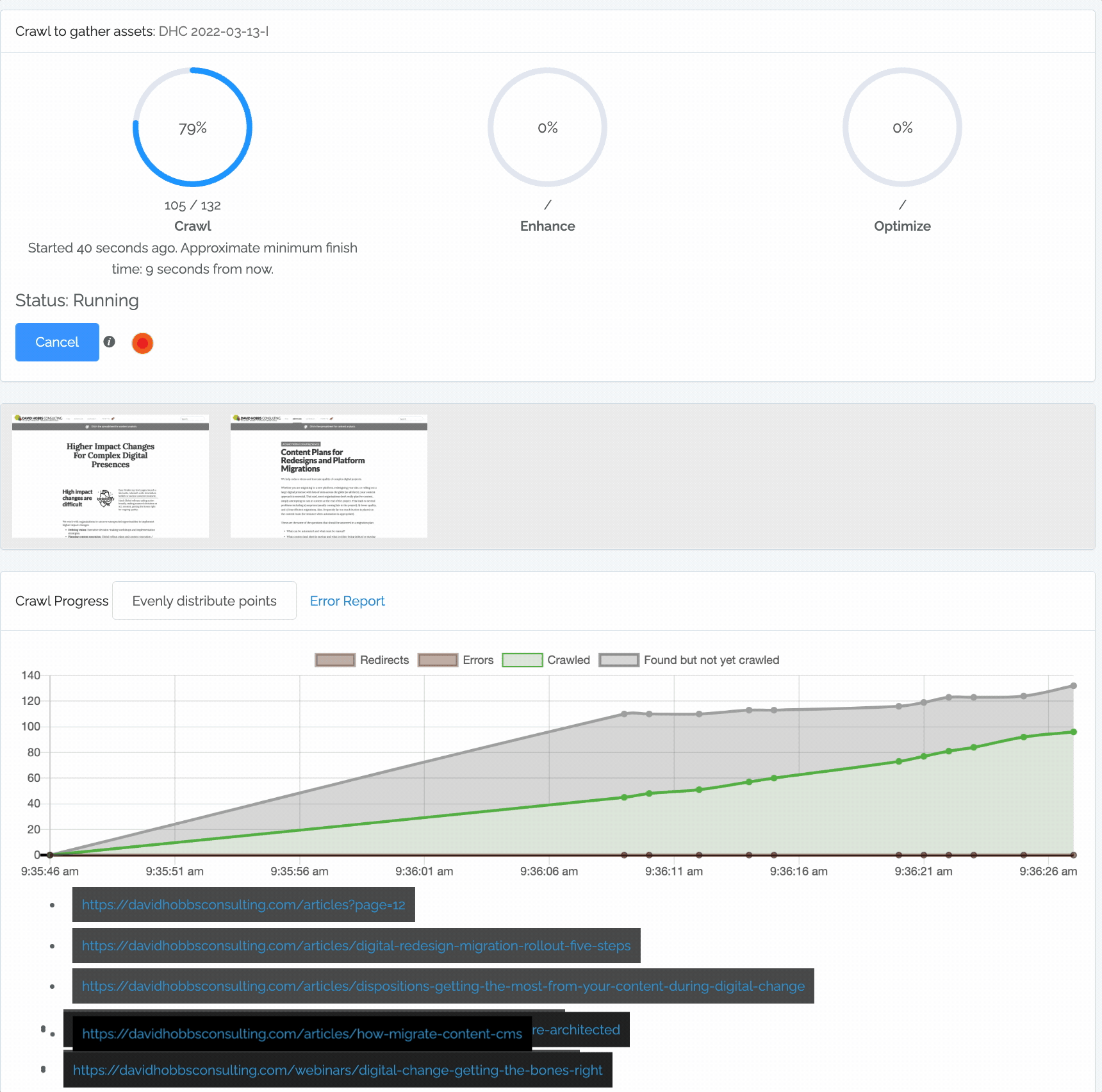
Content Chimera provides rich information when crawling:
The crawl circles (described above).
Sample screenshots taken during the crawl. Note that you can click on these to make annotations even while you are crawling.
- The chart shows:
Redirects. These are not considered a problem, so are simply shown below the zero line of the chart.
Errors. These are errors that resulted in not being able to get that page. You can click on the Error Report link to see the breakdown of errors.
Crawled. These are URLs that have already been crawled by Content Chimera.
Found but not yet crawled. These are URLs that Content Chimera has found on pages but has not yet crawled.
A dynamic list of URLs currently being crawled.
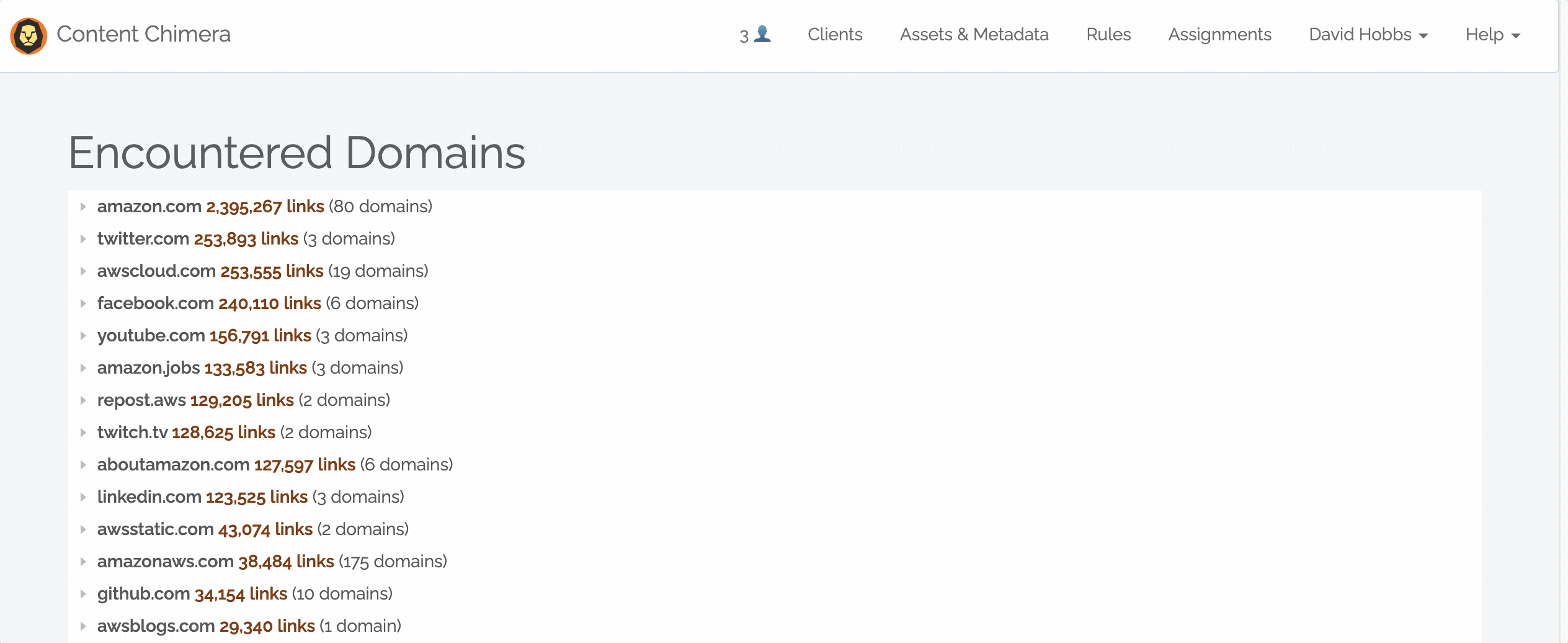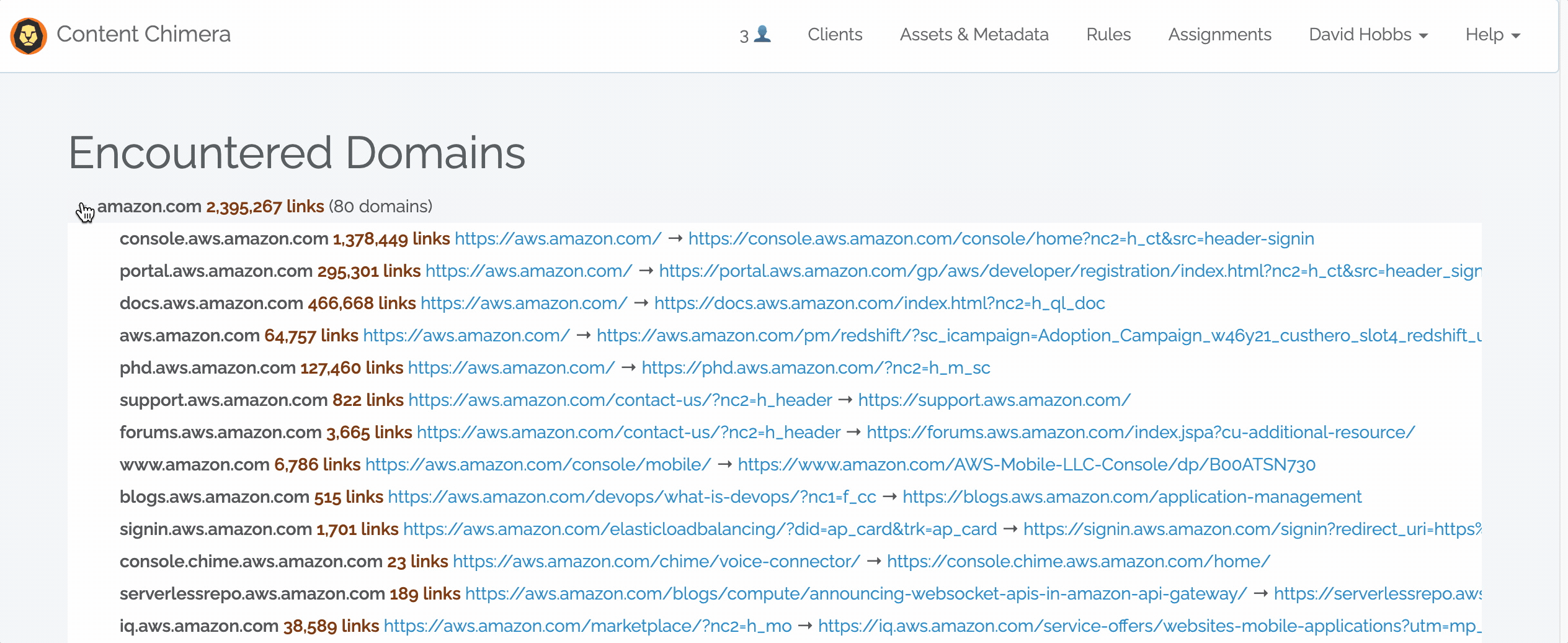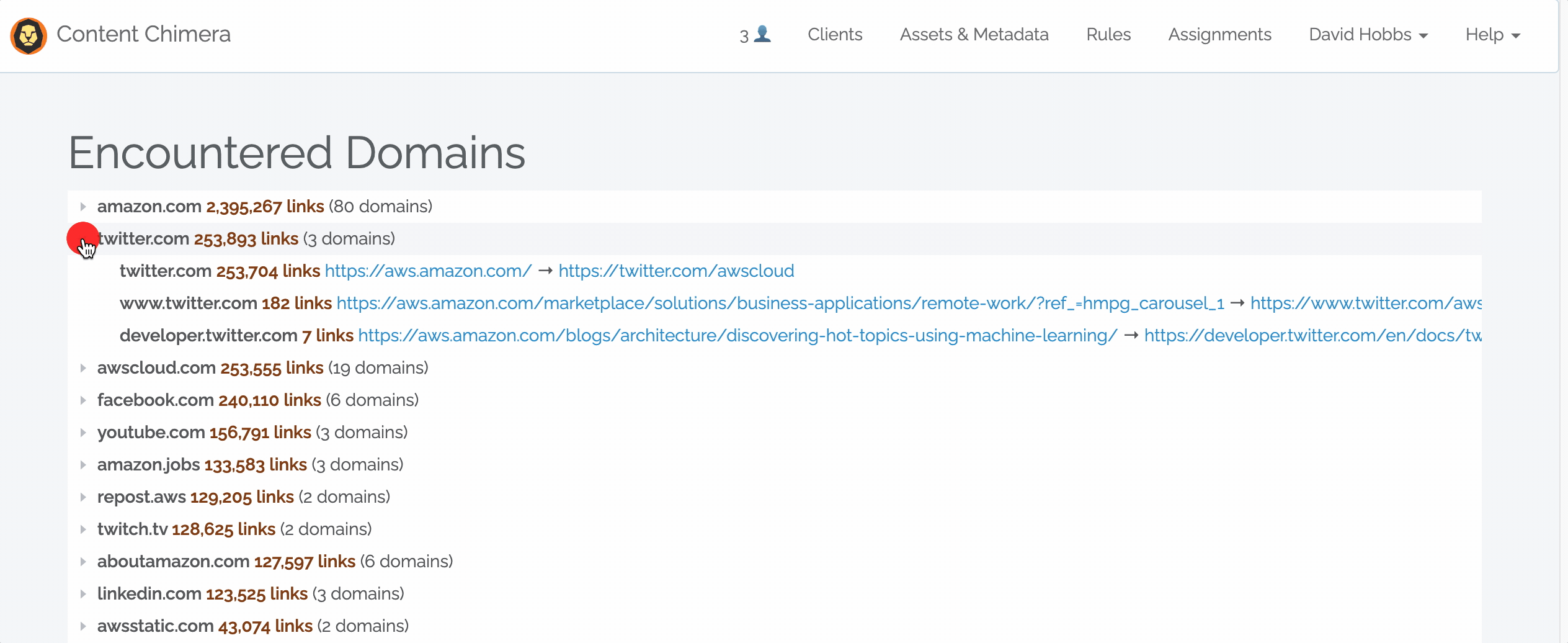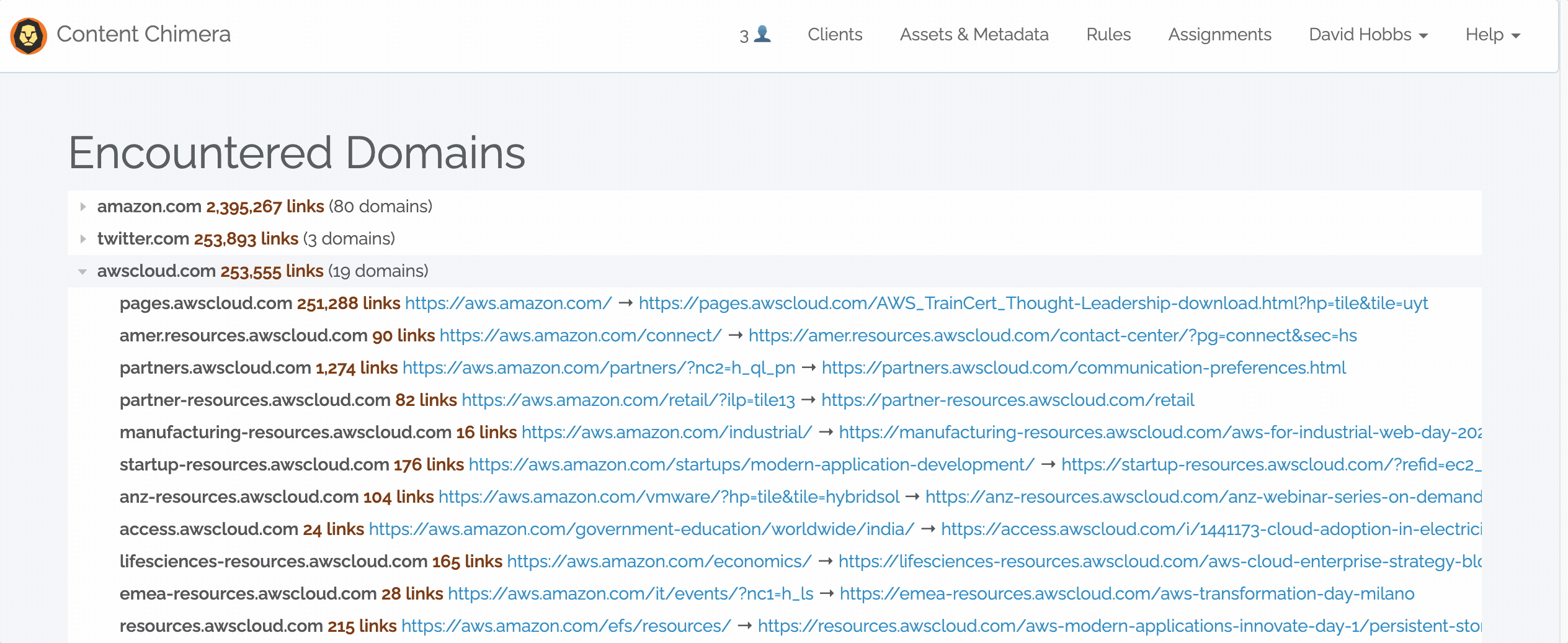
Encountered Domains¶
Once a crawl is complete a new “Encountered Domains Report” link appears above the crawl progress chart (next to the Error Report link). This report shows all the domains that were encountered during the crawl (across all pages in the crawl). The encountered domains report shows the following information:
The root domains (like “davidhobbsconsulting.com”) with the count of encountered links per domain. The most common root domain is shown at the top of the list.
When clicking on a root domain, it expands to show all the subdomains that were encountered. For each subdomain, an example link is show (the page that contains the link and the URL it was pointing to).