Deduplicating URLs¶
Content Chimera is honed for making content decisions. Many inventory tools are focused on lists of URLs. Of course Content Chimera can keep track of a large number of URLs, but it attempts to have a single record for each actual page with unique content.
To start with an example, consider these URLs:
https://www.test.com/ (http vs. https)
https://test.com/ (no www)
https://www.test.com/?session=825nadsfgklajsdfgy782345bnasdf2375hasdfs8f7 (URL parameters)
https://www.TEST.com (different casing)
https://www.test.com/page/2 (“folder” really standing as a variable name with the next parameter the value — here for the variable page having the value 2)
https://www1.test.com/ (probable different server or some other load balancing mechanism)
All of the above situations can be configured to be handed differently. By default, if the base URL (the URL entered on the Clients page when the site is first entered) is https://www.test.com/ then Content Chimera will consider this as three pages that need to be decided upon (the others will be considered duplicates):
https://www.test.com/page/2 (this case is not deduplicated now).
Crawling vs. Deduplicating¶
Assuming there are links to all the URLs listed above, Content Chimera will request each of the URLs. This is because it could be that Content Chimera has to look at the page in order to find actual content. Consider this example, where the pagination of the blog is needed to see posts 11-20. Content Chimera will look at all the pages, but in the charts and manifest will only list this as a single asset.
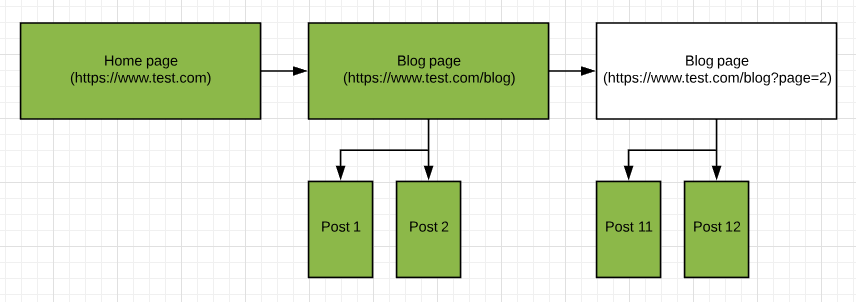
Note
You can configure what parameters to pay attention to. There are “keep” parameters and “stop” parameters. Keep parameters are those that will NOT be removed when deduping. On the other extreme are “stop” parameters — these are those that Content Chimera will only request once (The first time that it’s viewed it will be requested by Content Chimera. But if another URL is found with the stop parameter then it will only be requested at all if the combination of keep parameters have not been requested before).
