Long Processes and Progress Circles¶
Content Chimera is built to run very long processes. Consider crawling
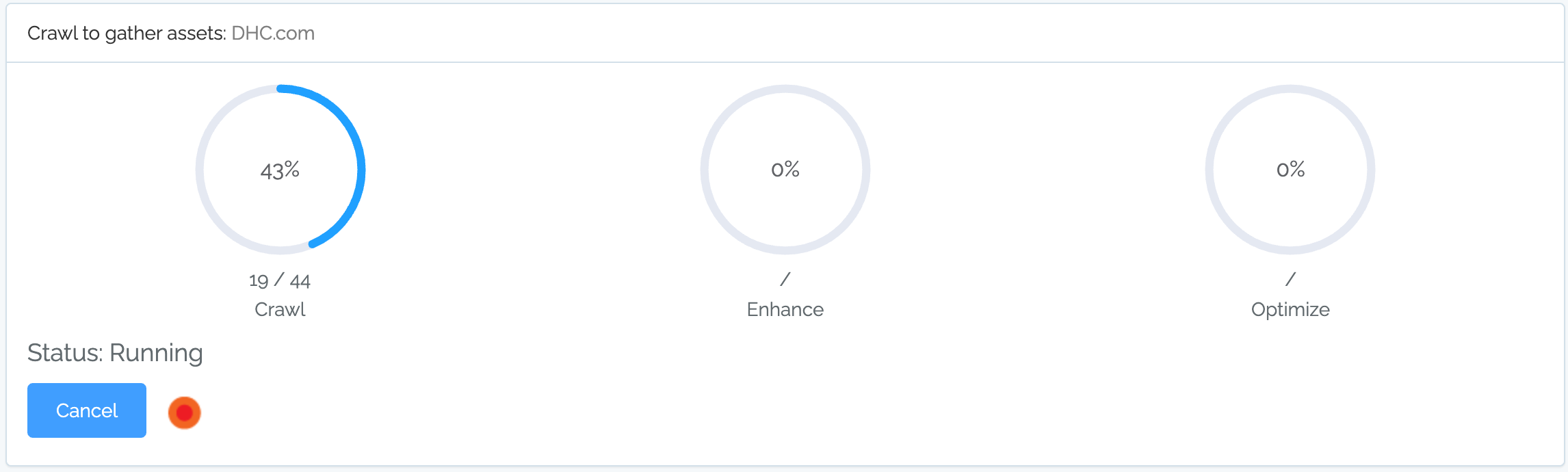
with three steps:
Crawl
Enhance
Optimize
For a very large crawl, the crawl could take hours or days (depending on configuration) with the other steps each taking over an hour.
Notably, many of these steps are helping you to avoid spending a lot of manual time in spreadsheets or other tools.
The progress page and the circles allow you to monitor how well the overall process is going.
Crawl¶
This is the most obvious type of process, and the only processing that some tools do. It is simply the crawl, following the links of the site to establish a list of URLs. Note that Content Chimera is also storing a cache of the site as well to enable subsequent processing (and to avoid hitting client web servers unnecessarily).
Enhance¶
This process pulls out information that is useful for making content decisions, such as the “folders” in the URL. Note that this step is separate from the crawl since it also runs on imports from other sources as well (so, although another crawler may not pull out the folders, you can still leverage folder information from assets imported from that other crawler).
Optimize¶
This is a behind-the-scenes process that optimizes the data for things like charting. In order to enable flexible processing of the data in the backend, the data is stored in multiple databases and tables, but to make many activities fast (most notably charting) the data is simplified. This is virtually always the last step of processing.
Assign¶
The process of applying rules to content in order to automatically make decisions.
