Migration Planning¶
Content Chimera was born out of migration and rollout planning.
It is specifically built on the following principles:
Migration planning is an iterative process. Content Chimera can quickly rerun analyses, since it mostly automated rather than manual. For instance, a change in the ruleset can quickly be rerun.
We can almost always use rules to make most content decisions. Read more about rules.
We can discover many migration “surprises” very early in the process, and we should be able to probe sites for this information without rehammering web servers. We can scrape out some key types of issues that plague migrations.
We can use charts to drive discussions about content and to communicate migration planning. For instance, the following chart quickly communicates how different content will be treated during a migration:
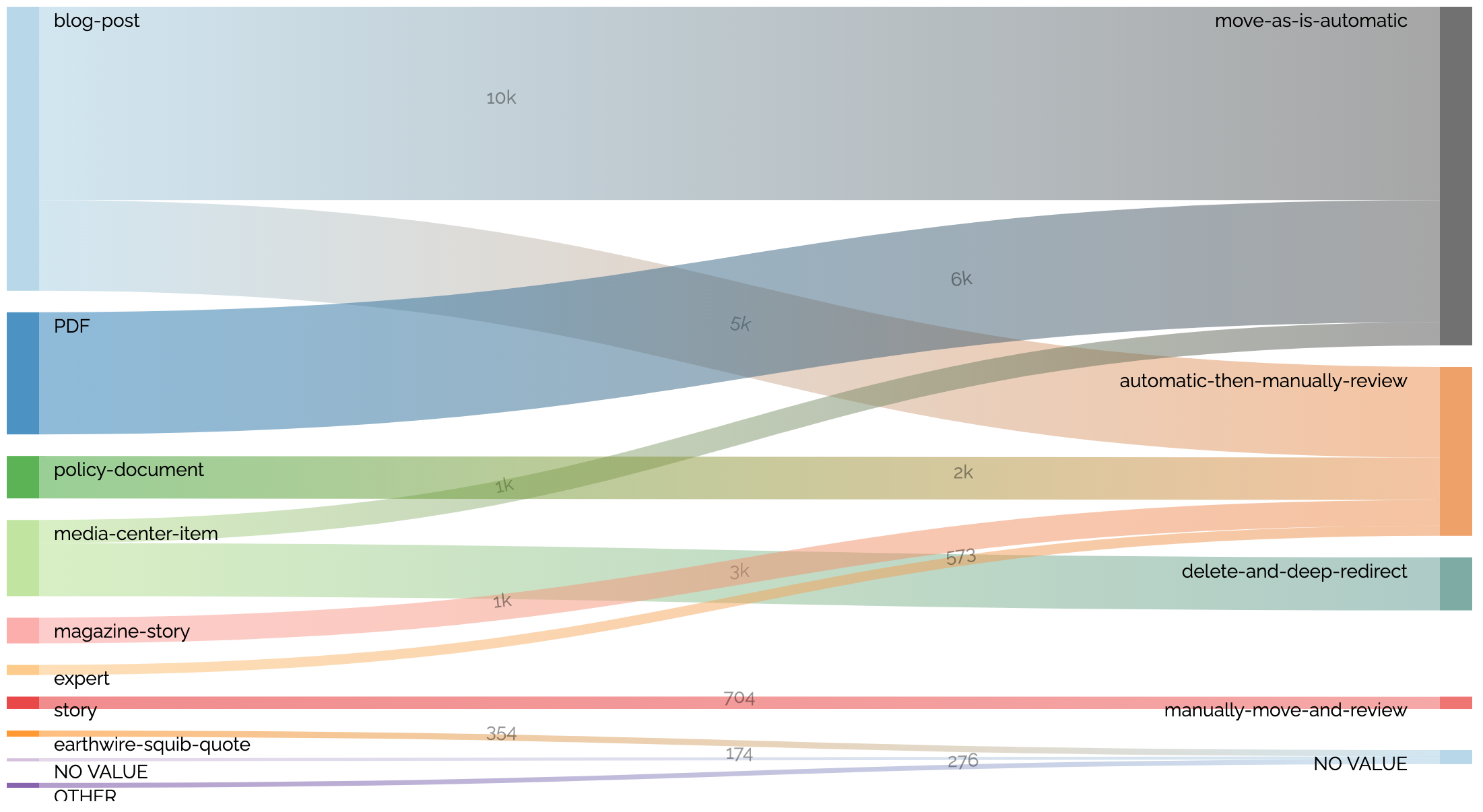
Steps in Content Chimera¶
As mentioned above, migration planning is iterative, so many of the steps below may be repeated as you hone your planning:
Import the list of URLs, either via crawling in Content Chimera or by importing from another source (either importing or natively crawling will also deduplicate and optimize).
Look at the basic site structure chart to see if the crawl looks complete (some parameters may need to be changed) and also to see if there are any obvious treatments. If so, make rules for these and run the ruleset.
Look at the distribution of file groups / file formats in order to determine if there are any further obvious rules that should be put in place.
Scrape out common migration issues, and look at the distribution of those issues.
Consider what additional information would help you make decisions, import that information, and define rules based on that new information.
Repeat until you have assigned all the content.
